SUMMARY: This chapter focuses on data manipulation and analysis using the Pandas library in Python. KEY TOPICS: Pandas DataFrame, Pandas Series, data cleaning, data aggregation, data visualization, handling missing data, merging and joining data, groupby operations, reading and writing data files, data transformation.
Correct answer: Option 1 —
Both statements are true.
Q241 Mark
Statement 1: head(n) returns the first n rows of a DataFrame.
Statement 2: tail(n) returns the last n rows.
Show answerHide answer
Correct answer: Option 1 —
Both statements are true.
Q251 Mark
Statement 1: read_csv() loads CSV data into a DataFrame.
Statement 2: to_csv() writes a DataFrame to a CSV file.
Show answerHide answer
Correct answer: Option 1 —
Both statements are true.
Q261 Mark
Statement 1: fillna() replaces missing values.
Statement 2: dropna() removes rows or columns containing missing values.
Show answerHide answer
Correct answer: Option 1 —
Both statements are true.
Case Study / Passage Questions1 question
Q273 Marks
A teacher has student marks in a CSV file with columns name maths physics chemistry. She loads it into a pandas DataFrame to compute the average marks per subject identify the topper and find students who scored less than 33 in any subject.
A 2-D tabular data structure in pandas is a:
ASeries
BDataFrame
CIndex
DTuple
Which method loads a CSV file into a DataFrame?
Aread_csv()
Bread_table()
Cread_excel()
Dload_csv()
Write the complete pandas program to compute averages identify the topper and list failing students.
Show answersHide answers
1. Option 2 — DataFrame
2. Option 1 — read_csv()
3. import pandas as pd; df = pd.read_csv('marks.csv'); df['avg'] = df[['maths' 'physics' 'chemistry']].mean(axis=1); topper = df.loc[df['avg'].idxmax()]; failed = df[(df['maths']<33) | (df['physics']<33) | (df['chemistry']<33)]. The mean(axis=1) computes row averages; idxmax() returns the index of the maximum; boolean indexing filters rows.
Table-Based Questions4 questions
Q285 Marks
Match each pandas object with its dimensionality and creator.
Object
Dimensions
How to create
Series
?
?
DataFrame
?
?
Index
?
?
Q296 Marks
For DataFrame df with 5 students predict each operation's result.
Method/attribute
Returns
df.head()
?
df.tail()
?
df.shape
?
df.columns
?
df.describe()
?
df.info()
?
Q306 Marks
Match each pandas method with its purpose.
Method
Purpose
read_csv()
?
dropna()
?
fillna()
?
groupby()
?
sort_values()
?
merge()
?
Q315 Marks
Predict the result of each pandas Series operation.
Operation on s = [10, 20, 30, 40]
Result
s[0]
?
s.sum()
?
s.mean()
?
s.max()
?
len(s)
?
s + 5
?
Picture-Based Questions3 questions
Q323 Marks
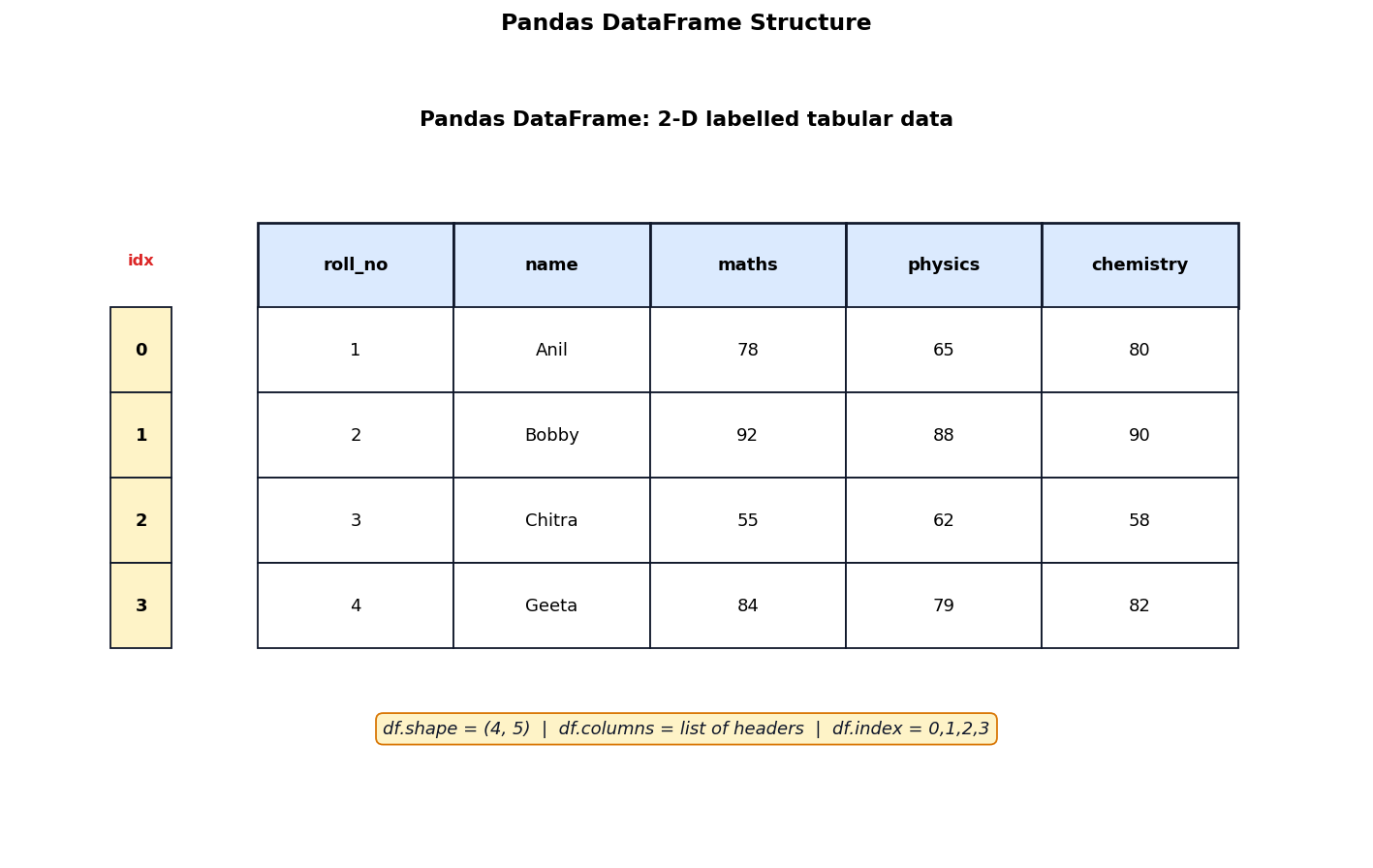
Study the pandas DataFrame structure and answer:
A 2-D labelled tabular data structure is called a:
ASeries
BDataFrame
CIndex
DList
The shape of the DataFrame shown is:
A(4, 5)
B(5, 4)
C(4, 4)
D(5, 5)
Discuss the structure of a pandas DataFrame and any three common attributes/methods.
Show answersHide answers
1. Option 2 — DataFrame
2. Option 1 — (4, 5)
3. A pandas DataFrame is a 2-D labelled tabular data structure with rows and columns. The leftmost is the index (0 1 2 3) and the top row is the column names. df.shape returns (rows columns); df.columns returns the column labels; df.head() shows the first 5 rows. The DataFrame can be created from CSV dictionary list of lists or another DataFrame.
Q333 Marks
Study the pandas Series structure and answer:
A 1-D labelled array in pandas is called a:
ASeries
BDataFrame
CIndex
DList
For s = pd.Series([78, 65, 92, 84, 55]) what is s[2]?
A78
B65
C92
D55
Discuss the structure and common operations of a pandas Series.
Show answersHide answers
1. Option 1 — Series
2. Option 3 — 92
3. A pandas Series is a 1-D labelled array. Each element has an integer index by default but custom labels can be assigned. Common operations include indexing (s[2]) sum() mean() max() min() len(). Series can be created from a list dictionary or NumPy array. It is the building block of a DataFrame.
Q343 Marks
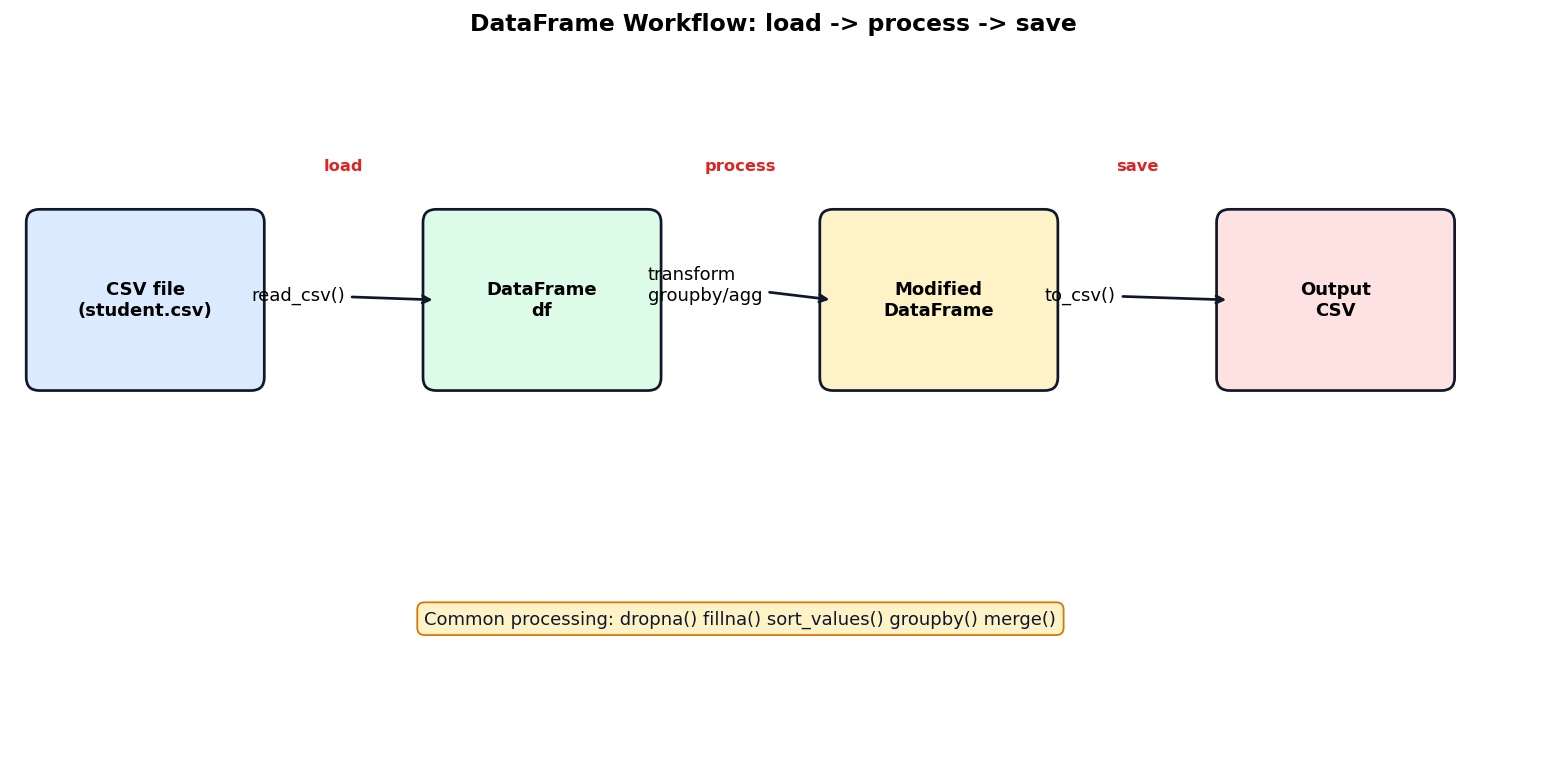
Study the DataFrame workflow diagram and answer:
Which method loads a CSV file into a DataFrame?
Aread_csv()
Bopen()
Cload()
Dimport_csv()
Which methods are commonly used in DataFrame processing?
Adropna()
Bfillna()
Cgroupby()
DAll of these
Discuss the typical workflow for processing data with pandas DataFrames.
Show answersHide answers
1. Option 1 — read_csv()
2. Option 4 — All of these
3. Typical DataFrame workflow: 1) Load data from CSV using read_csv(). 2) Inspect with head() info() describe(). 3) Process: handle missing values (dropna fillna) sort (sort_values) group and aggregate (groupby) merge with other DataFrames. 4) Save using to_csv() or to_excel().